Building AI Factchecking tools
Introducing crowdsourced data annotation to improve a factchecking algorithm


Problem
Full Fact had been selected from a shortlist of over 2.6k nonprofits, social enterprises and research institutions as the winner of the Google AI Impact Challenge for its work to automate factchecking and prevent the spread of fake news. Its AI team received $2m over three years alongside coaching from Google's AI experts to improve its suite of tooling for factcheckers around the world.
The AI team’s goal was to improve the precision scores of its machine learning model BERT by teaching it to recognise paraphrases of similar claims. This was an ambitious goal for a small social impact charity. My challenge was to figure out a way to help our AI team leanly generate the training data and understand what the process could look like for Full Fact going forwards.
What we did
Full Fact had previously relied on the work of factcheckers to annotate data and improve its machine learning model. This meant that our small charity had to down tools for several days to support the task, which was not ideal, so we wanted to explore whether we could lean on our dedicated supporters to assist with data annotation.
We started by identifying our key questions:
How much data could we realistically expect to generate from an exercise like this (an ideal would be about 5-10k usable annotations)
How could we design the claim annotation task so that we could ensure quality annotations from a crowd of volunteers who were not fact checkers?
How would we do this: would we have to build the software, buy it, or partner to get the task done?
I started by researching past papers on annotation strategy and task design for machine learning: this paper on crowdsourcing for machine learning by Jennifer Wortman Vaughan of Microsoft Research proved particularly useful, as did everything by crowdsourcing pioneer Luis von Ahn, creator of the CATPCHA and founder of Duolingo. This gave us a basic set of principles for what the task needed to include to be a success (for example, the inclusion of ‘gold standard’ tasks in annotation data to evaluate how well contributors are able to execute the data annotation task).
We also needed to find a way to serve the annotation task remotely to our volunteers. Our options ranged from reworking our Alpha annotation tools for this purpose; using a commercial annotation platform such as Crowdflower or Amazon’s mechanical turk; or looking at platforms for research like Zooniverse. After a call with Chris Lintott we decided to run with the Zooniverse: it was free, easy to use with remote users, aligned with our data ownership needs, and required no code/development resource to get up and running. The downsides were that it was primarily designed for image annotation, so we had to have some workarounds, and we couldn’t use it for future tasks on our roadmap (such as tagging entities in sentences, which we’d need something like Prodi.gy for). However for now it was sufficient for helping us understand how much data we could get and if the process worked without significant investment. Then we put out a call for help across our volunteer database, mailing list, and social media platforms to generate a sizeable pool of interested users.
We then set out to design our task, which we split into two key problems: claim detection, and claim matching. For claim detection, the goal was to fine tune our algorithm to categories the type of claims it was seeing, so that fact checkers could prioritise more harmful claims first. Work had already been done in this space to determine a category schema, based on patterns in Full Fact’s factchecks, so for our first experiment we sketched out a categorisation task, and ran a trial test. We quickly found that annotators found the task of sorting a claim into one of our categories difficult, and because of that few users were likely to ‘agree’ on the same answers. This produced less certainty in the data (ie. a poor ‘inter annotator’ score). This was not great.
As a result of rounds of iteration and kind feedback from our volunteers, we arrived at a reusable task design experience that users from non-factchecking backgrounds found simple to complete. This meant that by the end of the first pilot we managed to generate 8k annotations from our contributors for little investment, a superb achievement for a small factchecking charity.
If you want to read more about the work of Full Fact’s AI team, visit https://fullfact.org/ai/about/
What we achieved
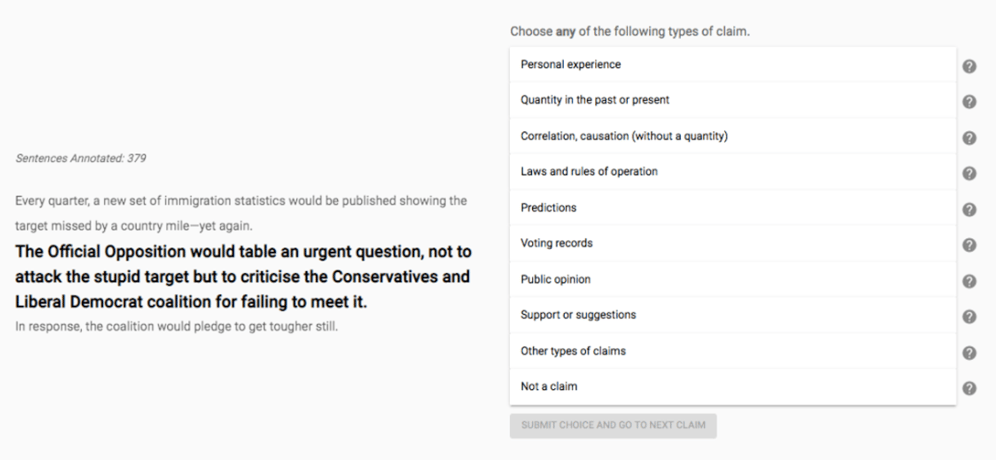
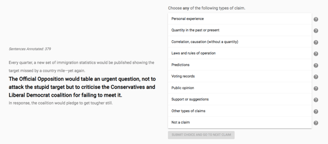


After analysing survey feedback, it transpired that users found it easier to keep one category in mind while reviewing lots of different sentences rather than reconsider each sentence for 10 different categories, especially if new to the task and the category concepts. So we reformatted the tasks into 9 separate questions, one per category, and asked annotators to select a binary yes/no answer instead. We ran a new experiment and found that the inter annotation agreement was between 80-90% across the different categories, much higher than our previous analysis.
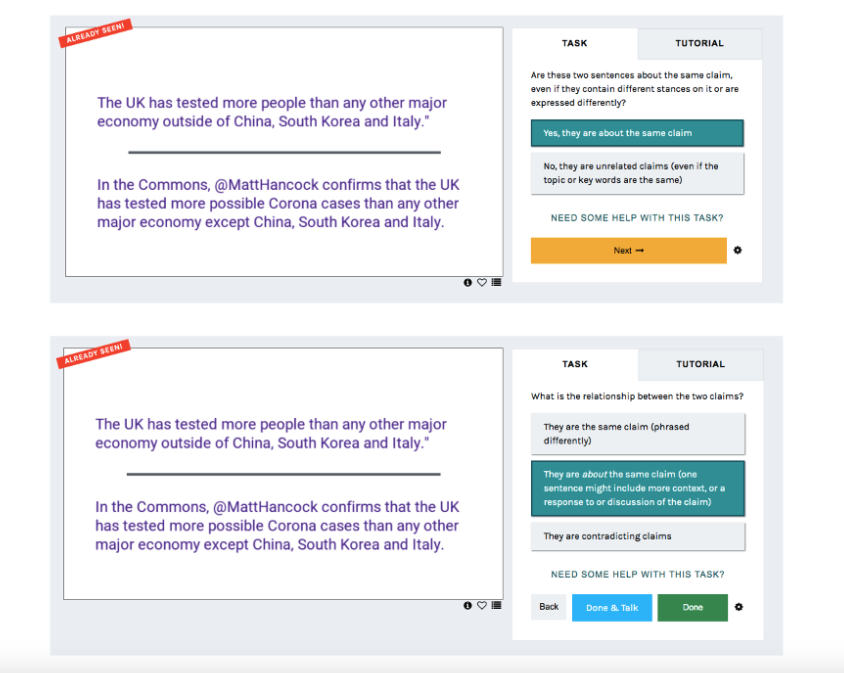
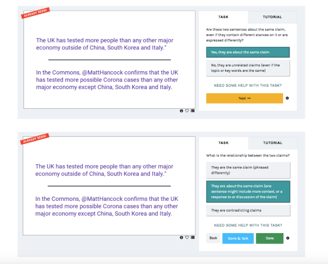
We then ran a pilot on claim matching data annotation, which is where we asked users to tell us how claims were related. For the first run, users read a sentence and selected from a list of 4 different options (do these sentences agree/disagree/are related/unrelated), but we quickly found that annotators were mostly marking claims as unrelated, which made the data not very useful to us. So we redesigned the task so that if a user encountered a pair of unrelated claims, they could dismiss it in order to quickly reach a matching claim that they could annotate for this. This two-stage process was much more effective.